


Profesor de la Facultat d’Òptica i Optometria de Terrassa (Universitat Politècnica de Catalunya).


Una imagen que se forma en el proyector de la memoria es la de un niño demasiado aplicado que, cuando el maestro de EGB pedía un trabajo para deberes (sí, había deberes), al salir de clase por la tarde iba a la biblioteca del pueblo a consultar los extensos volúmenes de la Enciclopedia Catalana.
Años más tarde, ya en la universidad, en la biblioteca del campus, el joven, que seguía siendo demasiado aplicado, ya no consultaba la enciclopedia, sino libros especializados, y alguna revista, para los trabajos que le seguían solicitando, incluido el trabajo gordo de final de grado (o mejor, de diplomatura).
Si estudiara hoy, ese joven muy probablemente no iría a la biblioteca, salvo necesidad extrema. Toda la información que necesitara para sus trabajos la tendría en el móvil o el portátil, y una simple búsqueda en Google (por mencionar un nombre) le aportaría muchos más recursos que el conjunto de la biblioteca del campus, y de toda la universidad.
Sin embargo, a diferencia de las entradas de la enciclopedia, o de los libros especializados, la información que hallaría en internet sería una mezcla amorfa de información fiable, medias verdades y falsedades (bien o mal intencionadas). Con espíritu crítico y dotado de los conocimientos necesarios, no le sería difícil, en principio, escoger quirúrgicamente la información veraz y rechazar el resto. Sin embargo, el espíritu crítico y los conocimientos se adquieren con la formación y la experiencia, no se poseen de forma innata (por lo general). No obstante, hay algunos espacios relativamente seguros, en los que el joven podría navegar sin peligro de monstruos marinos: los buscadores especializados, las bases de artículos científicos como Pubmed (por mencionar un nombre), los propios recursos digitales de la biblioteca.
 Entra en juego, a finales de 2022, ChatGPT, de la empresa OpenAI. ChatGPT se describe como un LLM (Large Language Model), con un interfaz tipo bot conversacional. Para romper el hielo de la conversación, le podemos hacer una pregunta; por ejemplo, que nos diga qué es un queratocono y cuáles son sus opciones de tratamiento. En sus versiones gratuitas, ChatGPT y herramientas similares, para responder a nuestras preguntas no realizan una búsqueda en internet a tiempo real, sino que tiran de los recursos empleados para su entrenamiento, que en caso de ChatGPT-3.5 incluyeron múltiples materiales, (exactamente cuáles no se conoce, pero debe suponerse que fueron libros, artículos, páginas web, etc.), publicados hasta 2021.
Entra en juego, a finales de 2022, ChatGPT, de la empresa OpenAI. ChatGPT se describe como un LLM (Large Language Model), con un interfaz tipo bot conversacional. Para romper el hielo de la conversación, le podemos hacer una pregunta; por ejemplo, que nos diga qué es un queratocono y cuáles son sus opciones de tratamiento. En sus versiones gratuitas, ChatGPT y herramientas similares, para responder a nuestras preguntas no realizan una búsqueda en internet a tiempo real, sino que tiran de los recursos empleados para su entrenamiento, que en caso de ChatGPT-3.5 incluyeron múltiples materiales, (exactamente cuáles no se conoce, pero debe suponerse que fueron libros, artículos, páginas web, etc.), publicados hasta 2021.
“Las respuestas de ChatGPT emplean un lenguaje a la vez coloquial y profundamente seguro de sí mismo”
Hasta qué punto estos materiales se escogieron en función de su fiabilidad, o a partir de otros criterios, tampoco se sabe. ¿Se incluyeron solo artículos de acceso libre, o también los que se encuentran tras una barrera de pago? ¿Se distinguió la fiabilidad de las fuentes según la jerarquía de la evidencia científica? ¿Se descartó el lenguaje sesgado, las teorías conspiratorias, el conocimiento científico ya desbancado?
El término bot conversacional no es baladí. Las respuestas de ChatGPT emplean un lenguaje a la vez coloquial y profundamente seguro de sí mismo, no duda, no dice “esto no lo sé, busca en la enciclopedia”. De hecho, existe un término muy adecuado para describir parte de sus respuestas: alucinación. Sirve para indicar que lo que no sabe o no encuentra, ChatGPT se lo inventa, o más que una invención pura y dura, lo que hace es una amalgama de información marginalmente relevante, y otra de correcta, pero de un ámbito distinto, y la extrapola sin ningún reparo para presentar un párrafo completo perfectamente creíble. Y nos lo creemos, ya que entra en escena un segundo término, el efecto halo, un sesgo cognitivo ampliamente documentado en la literatura que relata la tendencia a considerar cierto aquello que nos explican bien.
Para determinar la fiabilidad de ChatGPT en nuestro ámbito, junto con los profesores de la Facultat d’Òptica i Optometria de Terrassa Marc Argilés Sans y Lluís Pérez Mañà, realizamos un estudio en el que planteamos a este bot 30 preguntas relacionadas con la visión binocular, las lentes de contacto y la baja visión.

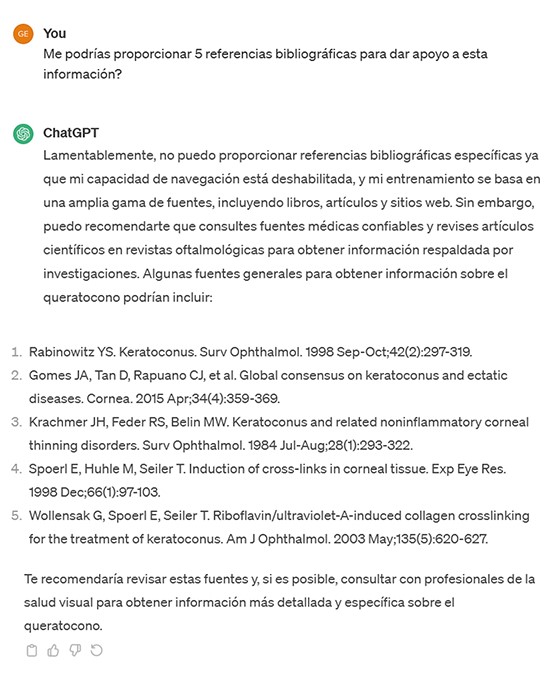
A cada una de las aportaciones de ChatGPT insistimos para que nos proporcionara, además, 5 referencias bibliográficas completas que respaldaran su respuesta. La corrección de las respuestas y del listado bibliográfico adjunto fueron examinadas por los tres autores del estudio, como expertos, y por un grupo de estudiantes del Grado y del Máster, como usuarios potenciales (y reales) de ChatGPT en sus labores académicas.
“En todos los casos se observó la tendencia del bot a alucinar parte de la información proporcionada”
Los resultados del estudio no sorprenden. Si bien los estudiantes por lo general valoraron mejor las respuestas de ChatGPT que los expertos, en todos los casos se observó la tendencia del bot a alucinar parte de la información proporcionada. Además, se halló una correlación directa entre la falta de fiabilidad de las respuestas y el grado de especificidad de la pregunta, siendo las preguntas más generales en las que proporcionó mejor información. En concreto, donde ChatGPT dio rienda suelta a su inventiva fue en las referencias bibliográficas de apoyo a sus respuestas. Así, de las 150 posibles referencias proporcionadas por el bot, solo un 24% se pudieron recuperar la base de datos Pubmed, y de éstas, muchas conducían a información en absoluto relacionada con la pregunta correspondiente.
Por su parte, se preguntó a los estudiantes si consideraban esta herramienta como útil para la realización de trabajos académicos, obteniendo valoraciones de entre 7 y 8,5 de mediana, en función del ámbito de estudio (respuestas posibles de 0 a 10). No hace falta ser muy perspicaz para sospechar que ChatGPT, o sus competidores, son utilizados con frecuencia, aprovechando que los párrafos pegados no se detectan como fraudulentos en los controles de plagio, de momento.
En un futuro muy próximo, y ya en algunas versiones premium de estas herramientas, se complementa la información almacenada con búsqueda a tiempo real de lo más reciente publicado en la web, por lo que muy posiblemente cada vez las respuestas proporcionadas sean mejores, con menos alucinaciones, con mayor peso de la evidencia científica. Pero, a medio plazo, todo parece indicar que seguirá siendo imprescindible un análisis crítico de las respuestas, por muy elegante y conversacional que sea el estilo con el que se redacten.
“Mire vuestra merced —respondió Sancho— que aquellos que allí se parecen no son gigantes, sino molinos de viento.” Miguel de Cervantes
NOTA: El estudio comentado en este artículo fue publicado en la revista Clinical Experimental Optometry a finales de 2023: Cardona G, Argiles M, Pérez-Mañá L. Accuracy of a Large Language Model as a new tool for optometry education. Clin Exp Optom. 2023 Dec 3:1-4. https://doi.org/10.1080/08164622.2023.2288174
Este artículo de opinión se publicó originalmente en la revista Optimoda correspondiente al primer semestre 2024.
Optimoda 217 Primer semestre 2024


")

")










